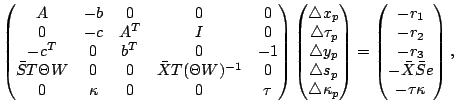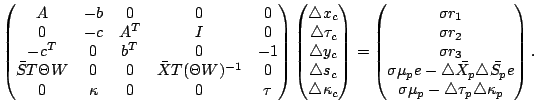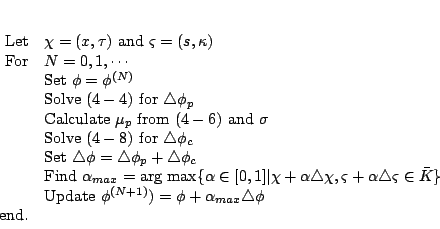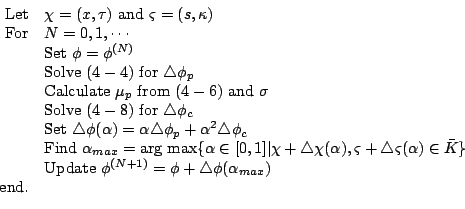Given a point
![]() with
with
![]() The predictor direction is found
by solving the following system:
The predictor direction is found
by solving the following system:
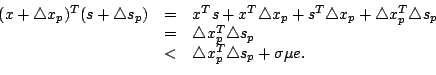
After expanding the left hand side of (4-7) and ignoring the
higher order terms
![]()
![]() and
and
![]() , one has
, one has
We describe two algorithms using the predictor direction and the corrector-centering direction mentioned above. All initial data are chosen as in Algorithm4.2.
Table 2 lists the results for these algorithms as
well as for the long-step path-following method, i.e., Algorithm
4.2 combined with Algorithm 4.3 and it compares
those with all four algorithms for SOCP problems we had evaluated
for the Seventh DIMACS implementation Challenge [7].
Similar to LP,
Table 2 also shows that in our test case Mehrotra's
version of the predictor-corrector method works better than
long-step path-following methods. Moreover, the quadratic
combination of predictor and corrector directions, i.e., Algorithm
4.5, has a few great results, but it is still worse
than Algorithm 4.4 overall, sometimes even worse than
the long-step algorithm.
Besides the above two algorithms,
we would have two variants for Algorithm 4.4. First,
inspired by [3,8], we implemented a code for the inexact
Newton method by adding a small residual term to the right hand
side. We use inexact_pc to denote this algorithm. Second, using
the predictor direction one more time if the reduction of ![]() is
significant. We denote this method as ppc. Moreover, instead of
solving the full system, we use the normal equations in Table
3. In order to solve large scale problems, solving
the full linear system is not as efficient as solving the normal
equations. Nevertheless, for some problems, the condition number
of the coefficient matrix for the normal equations is much larger
than for the full linear system as the point is getting closer to
the solution, for example, EX2-75 (see Figure 2).
is
significant. We denote this method as ppc. Moreover, instead of
solving the full system, we use the normal equations in Table
3. In order to solve large scale problems, solving
the full linear system is not as efficient as solving the normal
equations. Nevertheless, for some problems, the condition number
of the coefficient matrix for the normal equations is much larger
than for the full linear system as the point is getting closer to
the solution, for example, EX2-75 (see Figure 2).
| A. 4.4 | A. 4.5 | A.4.2 | SeDu | SDPT | MOSK | LOQO | |
| EX1-50 | 13 | 15 | 20 | 13 | 12 | 13 | 44 |
| EX1-75 | 16 | 14 | 21 | 16 | 11 | 13 | 44 |
| EX1-100 | 14 | 16 | 22 | 16 | 12 | 14 | 51 |
| EX1-200 | 17 | 17 | 23 | 16 | 12 | 16 | 60 |
| EX2-50 | 9 | 10 | 13 | 15 | 9 | 8 | 13 |
| EX2-100 | 8 | 13 | 13 | 12 | 10 | 8 | 14 |
| EX2-150 | 9 | 9 | 14 | 15 | 10 | 10 | 12 |
| EX2-200 | 10 | 9 | 14 | 14 | 10 | 10 | 13 |
| EX3-10-4 | 13 | 14 | 18 | 13 | 21 | 10 | 88 |
| EX3-20-4 | 11 | 13 | 16 | 14 | 16 | 10 | f |
| EX3-30-9 | 11 | 14 | 18 | 14 | 15 | 10 | f |
| EX3-40-9 | 13 | 14 | 18 | 14 | 12 | 10 | f |
| EX4-mark | 12 | 14 | 18 | 10 | na | 9 | na |
| EX4-return | 15 | 14 | 23 | 12 | na | 9 | na |
| EX4-risk | 14 | 16 | 21 | 12 | na | 9 | na |
| EX5-10 | 17 | 21 | 27 | 6 | na | 6 | na |
| EX5-20 | 17 | 25 | 26 | 7 | na | 6 | na |
| EX5-40 | 18 | 22 | 30 | 7 | na | 5 | na |
| EX5-80 | 23 | 24 | 31 | 8 | na | 5 | na |
| EX6-10 | 11 | 16 | 26 | 13 | na | 10 | na |
| EX6-20 | 11 | 15 | 35 | 15 | na | 10 | na |
| EX6-40 | 11 | 26 | 50 | 13 | na | 12 | na |
| EX6-60 | 14 | 26 | 62 | 14 | na | 11 | na |
| Alg.4.4(full) | ppc | inexact_pc | |
| EX1-50 | 13 | 16 | 13 |
| EX1-75 | 16 | 19 | 13 |
| EX1-100 | 15 | 19 | 14 |
| EX1-200 | 14 | 21 | 18 |
| EX2-50 | 9 | 13 | 12 |
| EX2-100 | 8 | 11 | 8 |
| EX2-150 | 9 | 15 | 8 |
| EX2-200 | 10 | 11 | 10 |
| EX3-10-4 | 13 | 15 | 13 |
| EX3-20-4 | 11 | 17 | 15 |
| EX3-30-9 | 11 | 17 | 11 |
| EX3-40-9 | 13 | 19 | 13 |
| EX4-mark | 12 | 15 | 13 |
| EX4-return | 15 | 17 | 13 |
| EX4-risk | 14 | 19 | 13 |
| EX5-10 | 17 | 20 | 18 |
| EX5-20 | 17 | 27 | 29 |
| EX5-40 | 18 | f | 29 |
| EX5-80 | 23 | 43 | 29 |
| EX6-10 | 11 | 20 | 11 |
| EX6-20 | 11 | 11 | 11 |
| EX6-40 | 11 | 17 | 12 |
| EX6-60 | 14 | 17 | 13 |
We also show the results for using the full system and the normal equations. In the tables, 'f' denotes failure. SDPT3 and LOQO do not handle rotated cone constraints. Our best method performs quite well compared to the other codes. As the evaluation [7] had shown, the code MOSEK which is the only one specialized for convex optimization including SOCP is the most robust and efficient for such problems. Its performance is very comparable to that of our best method because the approaches are very similar except for a better exploitation of sparsity in MOSEK. SeDuMi uses also a self-dual embedding technique and was mainly optimized for robustness, which is reflected in the uniformly moderate but not lowest iteration counts and the lack of failures. SDPT3 uses an infeasible path-following method and could probably handle larger sparse cases nearly as well as MOSEK. LOQO finally, is a general NLP code and it treats the SOCP problems as smoothed nondifferentiable NLPs which in some cases leads to larger iteration counts.